Important Notice
⚠️ Some models introduce new Interleaved Thinking behaviors.On SiliconFlow, DeepSeek V3.2 and GLM-4.7 may emit Interleaved Thinking-related structured output when using the serverless model API—most commonly in tool-calling flows.
To ensure correctness, stability, and optimal performance, please follow the guidelines below.
Overview
On SiliconFlow, Interleaved Thinking is currently supported by:- DeepSeek V3.2
- GLM-4.7
- Agent-style orchestration
- Tool-calling scenarios
- Coding and debugging
- Multi-step tasks that benefit from intermediate tool outputs
1. What is Interleaved Thinking?
With Interleaved Thinking, a model can:- Decide whether it needs to call a tool
- Call a tool
- Receive tool results
- Continue from intermediate outputs
- Decide the next step (call another tool or produce a final answer)
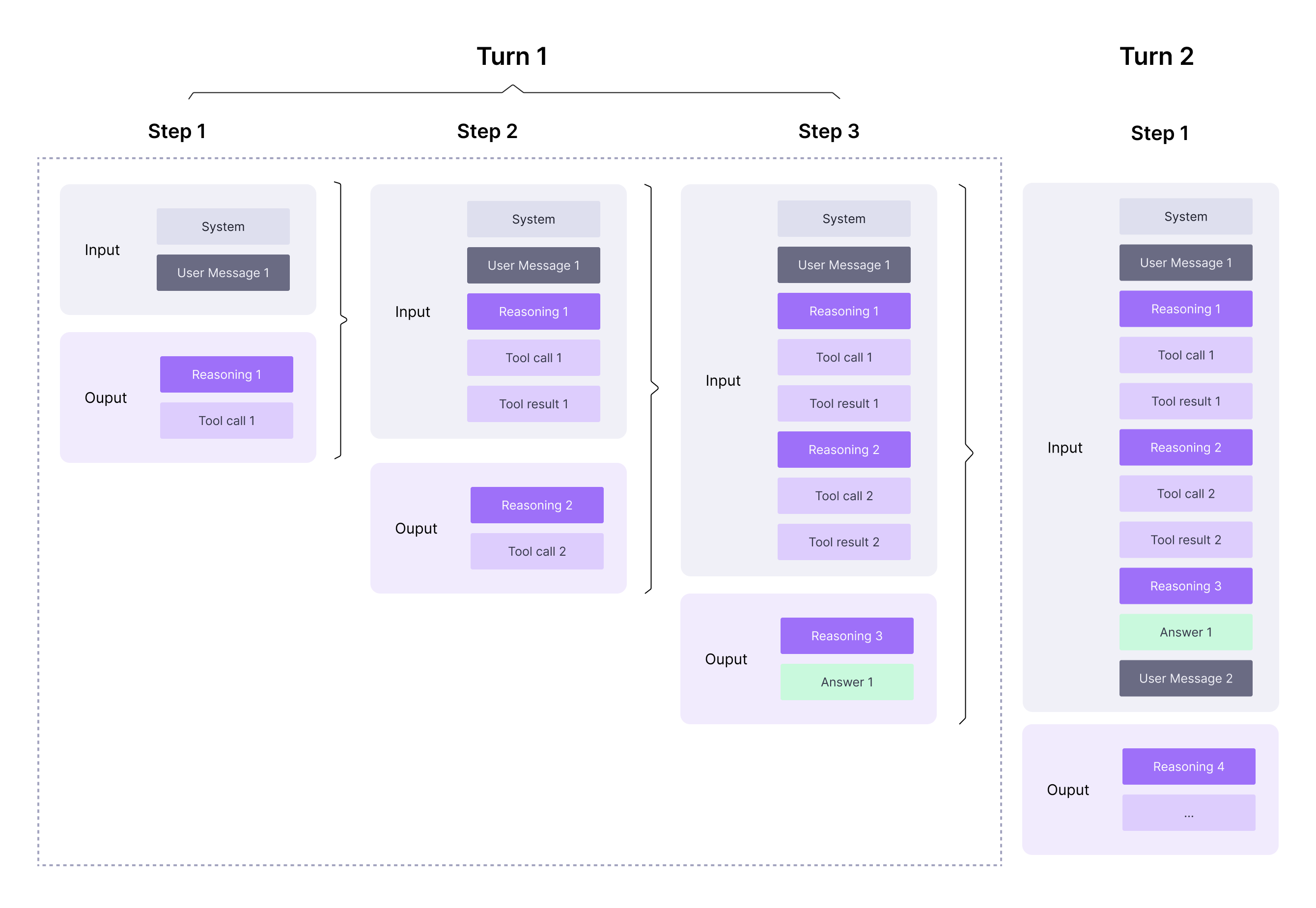
Diagram: Turn/Step structure with tool results
The diagram below illustrates how a single Turn can contain multiple Steps, and how the model may continue producingreasoning_content after tool results (i.e., after you send role="tool" messages).For correct tool-calling behavior, preserve and replay
reasoning_content exactly as received across the entire sequence.
2. Tool Calling: The Non-Negotiable Rule
When using tool calling with DeepSeek V3.2 or GLM-4.7, the API may return additional structured output in a dedicated field:reasoning_content
reasoning_content exactly as received, and send it back unchanged in subsequent requests.
What must be preserved (including after tool results)
To be explicit: preservation is required not only forreasoning_content produced after user messages, but also for reasoning_content produced after tool results.
In tool-enabled flows, the model may produce reasoning:
- before any tool call,
- between multiple tool calls,
- and after receiving tool results (i.e., after you send
role="tool"messages and the model continues).
reasoning_content exactly as generated.
This includes:
- Content emitted before any tool calls
- Content emitted between tool calls (multi-step tool chaining)
- Content emitted after tool results
- Any
reasoning_contentsegments produced across turns (keep the original order)
What you must NOT do
❌ Do NOT:- Modify the text
- “Clean up” or post-process it
- Merge or split segments
- Reorder segments
- Drop it while keeping only normal assistant text
- Broken multi-step behavior around tools
- Instability across tool calls
- Reduced cache efficiency and degraded output quality
3. Client Handling Checklist (Recommended)
When receiving responses:- Accumulate normal assistant text from
content(ordelta.contentif streaming) - Accumulate Interleaved Thinking text from
reasoning_content(ordelta.reasoning_contentif streaming) - Collect tool requests from
tool_calls(ordelta.tool_callsif streaming)
contentreasoning_content(verbatim, complete, in the exact original order)tool_calls(as received)
delta.*), not what you must preserve.
4. Example: Interleaved Thinking + Tool Calling (DeepSeek V3.2)
This example demonstrates DeepSeek V3.2 on SiliconFlow.The same pattern also applies to GLM-4.7.
5. Using GLM-4.7 Instead
To switch the example to GLM-4.7, change:reasoning_content after tool results.
Summary
For DeepSeek V3.2 and GLM-4.7 on SiliconFlow:- Interleaved Thinking enables multi-step, tool-aware execution
- With tool calling, you must preserve and replay
reasoning_contentverbatim—including any reasoning produced after tool results - Never modify, drop, merge/split, or reorder
reasoning_content